

How To Execute A Sored Procedure From Aws Data Pipeline

A relational database that supports procedural language allows you to assign a value to a local variable within stored procedures by using the SELECT argument. Teradata and Oracle databases, for example, support the SELECT INTO clause for assigning a value to a local variable.
In this article, we'll expect at how to use the Redshift SELECT INTO clause within Stored Procedures to assign a subquery value to a local variable.
In Redshift, the SELECT INTO argument retrieves data from ane or more database tables and assigns the values to variables. To assign a previously alleged variable within a stored process or a RECORD type variable, use the Redshift SELECT INTO.
Table of Contents
- Introduction to Amazon Redshift
- Key Features of Redshift
- SELECT INTO Variable in Redshift
- Redshift SELECT INTO Syntax
- Redshift SELECT INTO Example
- Decision
Introduction to Amazon Redshift

Amazon Redshift is a petabyte-scale information warehouse solution powered by Amazon Web Services. It is also used for large database migrations considering it simplifies data management.
Amazon Redshift's compages is based on massively parallel processing (MPP). Amazon Redshift Databases are based on Column-Oriented Databases and are designed to connect to SQL-based clients and BI tools. This enables users to have constant admission to data (structured and unstructured) and aids in the execution of Complex Analytic queries.
Amazon Redshift also supports standard ODBC and JDBC connections.
Because Amazon Redshift is a fully-managed Data Warehouse, users can automate authoritative tasks to focus on Information Optimization and Data-driven Business decisions rather than performing repetitive tasks.
Each Cluster in an Amazon Redshift Data Warehouse has its own set up of computing resources and runs its own Amazon Redshift Engine with at least one Database.
Key Features of Redshift
- Massively Parallel Processing (MPP): A big processing job is divided into smaller jobs that are so distributed across a cluster of Compute Nodes. These Nodes process data in parallel rather than sequentially.
- Integrated Analytics Ecosystem: AWS'south built-in ecosystem services make Finish-to-Stop Analytics Workflows easier to manage while avoiding compliance and operational stumbling blocks. Some well-known examples include AWS Lake Formation, AWS Mucilage, AWS EMR, AWS DMS, AWS Schema Conversion Tool, and others.
- SageMaker Support: A must-have for today'due south Data Professionals, it enables users to build and train Amazon SageMaker models for Predictive Analytics using information from their Amazon Redshift Warehouse.
- ML For Optimal Performance: Amazon Redshift has robust Car Learning (ML) capabilities that enable high throughput and speed. Its sophisticated algorithms predict incoming inquiries based on specific factions, allowing important jobs to exist prioritized.
- Fault Tolerance: Amazon Redshift continuously monitors its Clusters and Nodes. When a Node or Cluster fails, Amazon Redshift replicates all data to healthy Nodes or Clusters automatically.
Hevo Data, a No-code Data Pipeline helps to Load Data from any data source such every bit Databases, SaaS applications, Cloud Storage, SDKs, and Streaming Services and simplifies the ETL process. It supports 100+ Data Sources (including forty+ free information sources) and is a 3-footstep process by but selecting the information source, providing valid credentials, and choosing the destination. Hevo loads the information onto the desired Data Warehouse such as Amazon Redshift, enriches the data, and transforms it into an analysis-ready form without writing a single line of lawmaking.
Its completely automated pipeline offers data to exist delivered in real-fourth dimension without any loss from source to destination. Its error-tolerant and scalable architecture ensure that the data is handled in a secure, consistent manner with zero information loss and supports unlike forms of data. The solutions provided are consequent and work with different Business organization Intelligence (BI) tools as well.
Get Started with Hevo for complimentary
Check out why Hevo is the Best:
- Secure: Hevo has a fault-tolerant architecture that ensures that the information is handled in a secure, consistent style with nothing data loss.
- Schema Direction: Hevo takes abroad the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Minimal Learning: Hevo, with its simple and interactive UI, is extremely simple for new customers to work on and perform operations.
- Hevo Is Built To Scale: As the number of sources and the volume of your information grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in existent-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo squad is bachelor circular the clock to extend infrequent support to its customers through chat, e-mail, and support calls.
- Live Monitoring: Hevo allows you to monitor the data flow and check where your data is at a particular point in fourth dimension.
Sign upward here for a xiv-twenty-four hour period Costless Trial!
SELECT INTO Variable in Redshift
In Redshift, the SELECT INTO statement retrieves data from 1 or more database tables and assigns the values to variables. To assign a previously declared variable within a stored process or a RECORD blazon variable, use the Redshift SELECT INTO.
- Redshift SELECT INTO Syntax
- Redshift SELECT INTO Example
Redshift also selects and inserts rows from whatsoever query into a new table. Yous tin can choose between creating a temporary and a persistent tabular array. This syntax is like to the T-SQL SELECT INTO syntax used in Microsoft SQL Server.
Redshift SELECT INTO Syntax
Rows defined past any query are selected and inserted into a new table. Yous can cull betwixt creating a temporary and a persistent table.
[ WITH with_subquery [, ...] ] SELECT [ TOP number ] [ ALL | Singled-out ] * | expression [ AS output_name ] [, ...] INTO [ TEMPORARY | TEMP ] [ Tabular array ] new_table [ FROM table_reference [, ...] ] [ WHERE condition ] [ GROUP Past expression [, ...] ] [ HAVING condition [, ...] ] [ { Wedlock | INTERSECT | { EXCEPT | MINUS } } [ ALL ] query ] [ ORDER BY expression [ ASC | DESC ] [ LIMIT { number | ALL } ] [ OFFSET start ] See below for more data on the parameters of this control.
- WITH: A WITH clause is an optional clause that comes before a query'southward SELECT listing. WITH specifies one or more than mutual table expressions.
- SELECT: The SELECT listing specifies the columns, functions, and expressions that the query should return. The query's output is represented by the list.
- FROM: A query'southward FROM clause lists the tabular array references (tables, views, and subqueries) from which data is selected.
- WHERE: The WHERE clause includes conditions that either joins tables or utilise predicates to tabular array columns.
- GROUP BY: The Grouping BY clause specifies the query's grouping columns.
- HAVING: The HAVING clause adds a condition to the intermediate grouped effect fix returned by a query.
- UNION, INTERSECT & EXCEPT: The set operators Spousal relationship, INTERSECT, and EXCEPT are used to compare and merge the results of two separate query expressions.
- ORDER By: The ORDER By clause sorts a query's result set.
Redshift SELECT INTO Example
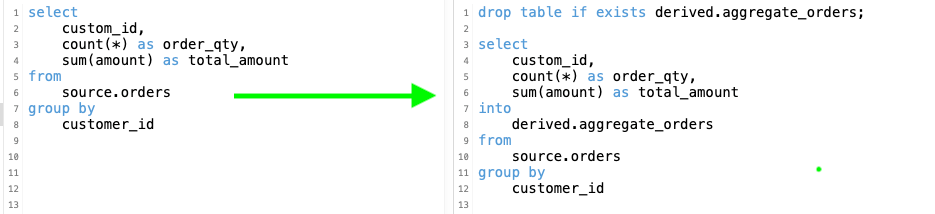
Create a NEW EVENT table by selecting all of the rows from the EVENT table:
select * into newevent from event; Enter the amass query result into a temporary table called PROFITS:
select username, lastname, sum(pricepaid-committee) as profit into temp table profits from sales, users where sales.sellerid=users.userid group past 1, ii order by 3 desc; Another Example
Conclusion
This blog goes into great detail almost the Redshift SELECT INTO statement. Information technology likewise provides an overview of Amazon Redshift earlier delving into the Redshift SELECT INTO statement.
The Redshift SELECT INTO command is elementary to use and follows the PostgreSQL querying protocol. However, the user should be aware of some limitations. Most of the time, the query validation will not return an mistake. It may deport out its own automatic conversions.
To become more than efficient in handling your Databases, information technology is preferable to integrate them with a solution that can deport out Data Integration and Management procedures for you without much ado and that is where Hevo Data, a Cloud-based ETL Tool, comes in. Hevo Data supports 100+ Data Sources and helps yous transfer your data from these sources to Data Warehouses like Amazon Redshift in a thing of minutes, all without writing whatsoever code!
Visit our Website to Explore Hevo
Want to take Hevo for a spin? Sign Upwardly for a 14-day free trial and experience the characteristic-rich Hevo suite kickoff hand.
Share your experience of agreement the Redshift SELECT INTO variable in the comments section below!
No-lawmaking Data Pipeline for Amazon Redshift
Continue Reading

Become a Contributor
Yous can contribute any number of in-depth posts on all things information.
Write for Hevo

How To Execute A Sored Procedure From Aws Data Pipeline,
Source: https://hevodata.com/learn/redshift-select-into/
Posted by: morrishisems.blogspot.com
0 Response to "How To Execute A Sored Procedure From Aws Data Pipeline"
Post a Comment